
sito

sito

sito

sito

sito


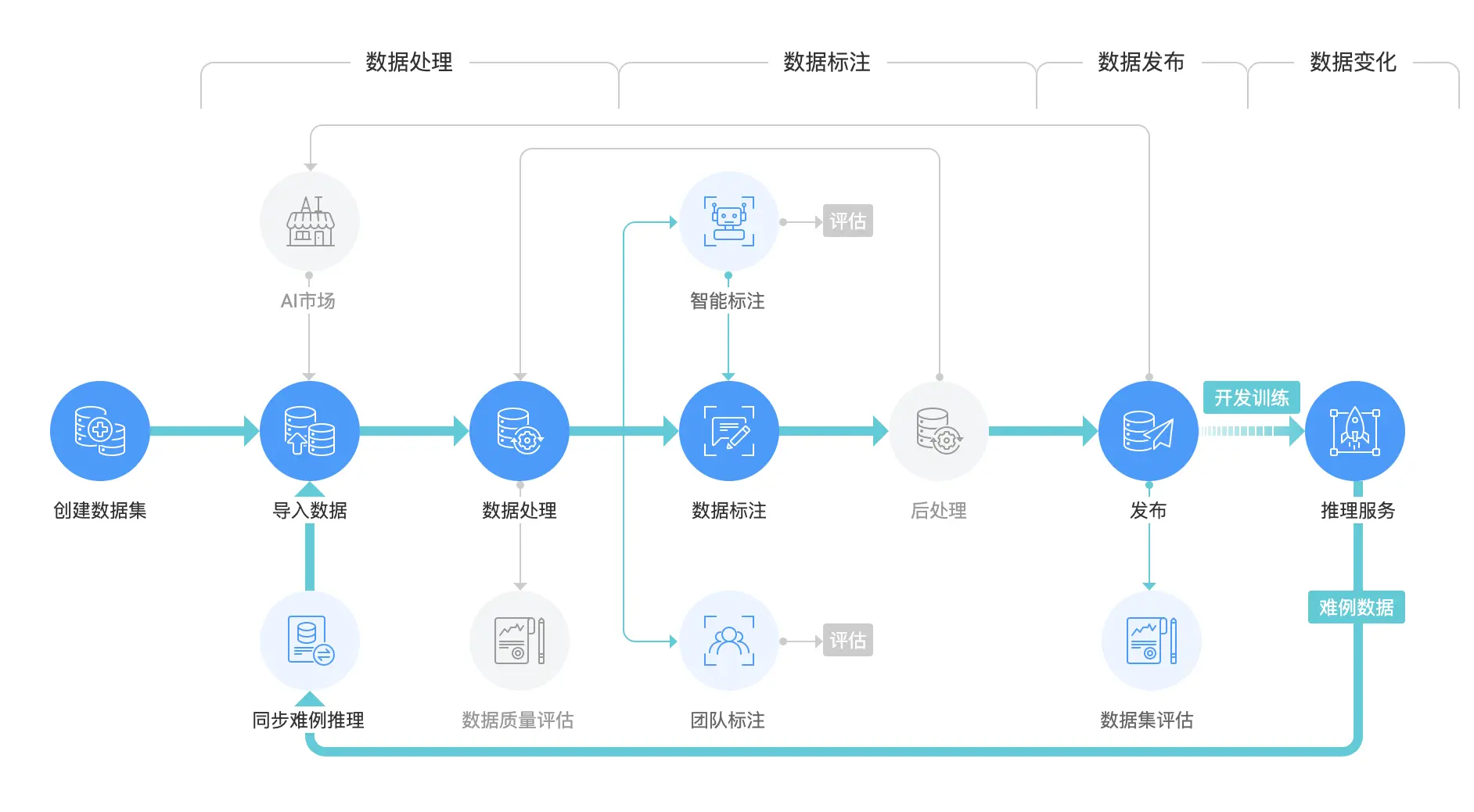
随着GPT-4、Qwen2.5Max等大模型训练数据量从GB级跃升至“万亿tokens”级(2025年Qwen2.5Max数据量超20万亿tokens),数据标注需求呈现三大新特点:
- 全生命周期覆盖:预训练阶段需“海量弱标注数据”,监督微调阶段需“精准指令数据”,强化学习阶段需“人类偏好反馈数据”,各环节需求差异显著。
- 质量要求严苛化:需满足“事实准确、语义一致、价值安全、场景完备”四大标准,医疗、金融等领域甚至需专业资质人员参与标注。
- 工程化能力升级:需支持万人级并发标注、全链路数据追溯,多模态场景(图文、音视频)还需跨模态对齐技术。
值得关注的是,DeepSeek等企业已探索新范式——通过“自动生成数据集+数据蒸馏+强化学习”,减少传统人工标注依赖,推动行业向“智能标注”转型。
 固话
固话 地址
地址 微信
微信 邮箱
邮箱 0832-2112880
0832-2112880


