
sito

sito

sito

sito

sito


随着大模型的蓬勃发展,数据标注需求呈现海量增长。从2018年GPT-1的4.6GB训练数据,到2025年Qwen2.5Max超过20万亿tokens的数据量,大模型对数据规模和质量的追求近乎苛刻。
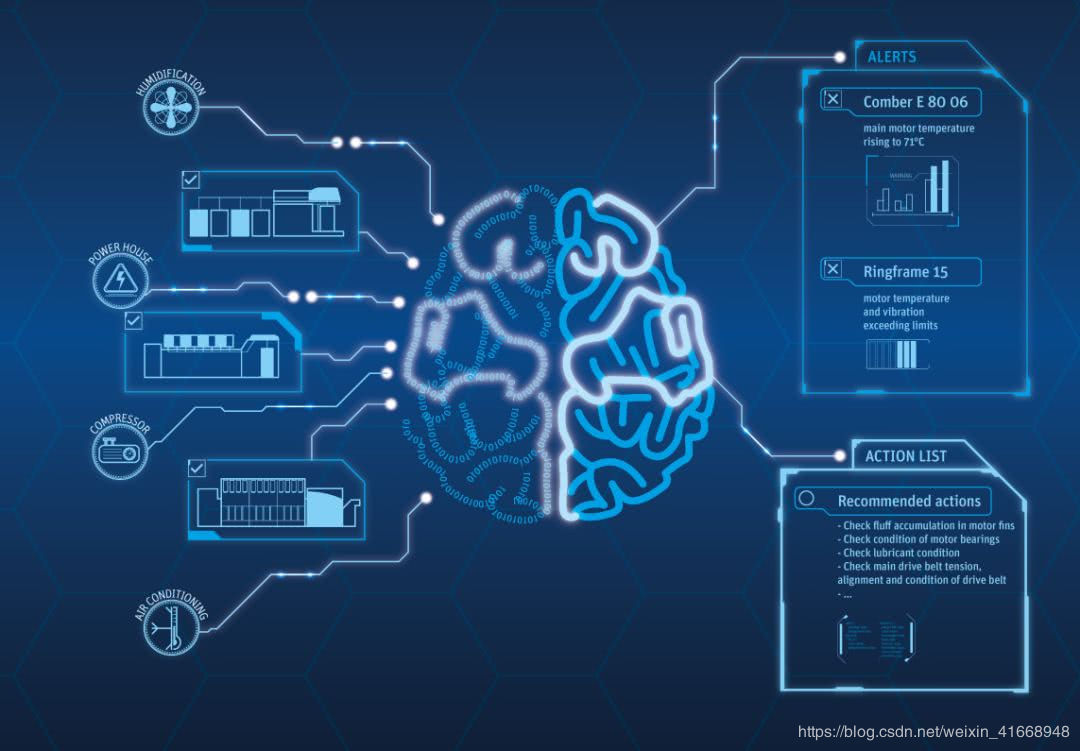
大模型对数据标注提出了更高要求:在预训练阶段需要海量弱标注数据的清洗与去噪;在监督微调阶段要求高质量指令数据的精准标注;在强化学习阶段依赖人类偏好反馈标注。这些变化推动数据标注从劳动密集型向知识密集型转变。
值得一提的是,报告特别指出DeepSeek等先进模型开启了数据标注新范式,通过自动生成高质量数据集、数据蒸馏+人类协同技术等方式,显著提升了数据标注的效率和质量。
信息来源:制造前沿
 固话
固话 地址
地址 微信
微信 邮箱
邮箱 0832-2112880
0832-2112880


